
I recently had the chance to work with a client (let’s call them ACME Corp.) that is emerging out of the startup phase. Like many startups, this client has created a product, found a viable market, and had challenges scaling what they’d built.
The product was built using Google’s Firebase Real-Time Database (RTDB) for storage. This data store helped ACME quickly develop and bring their product to market and was paired with a UI/SPA that communicates directly with RTDB. While this worked to help get off the ground, ACME quickly ran into scalability issues and began re-architecting the storage and data access for the product.
Part of their re-architecture efforts was to create new REST back-end services backed by Postgres. While they had an idea of what they wanted the new services to do, they did not know how to get the data out of RTDB and into the appropriate services. Axian was brought in to help with this journey—migrate the data and help build the new back-end.
Forging a path forward
In order for ACME to consider the effort successful, we needed to meet a list of key requirements and constraints.
Goals and constraints
- No downtime for their legacy applications!
- Minimal changes to their legacy applications and data. The client did not want to invest in any modifications to their legacy platform.
- Don’t bring down the database (RTDB)! They were already having trouble scaling and we couldn’t make this worse!
- Help to re-design their data model in the new services. This meant a lift-and-shift approach was not viable.
- Author and use APIs as a client application would. We were asked to not create one-off APIs for migration, if possible.
Solution Design
With these requirements and constraints mind, we began designing a solution for them. Using a solution that heavily relied on technologies from Google Cloud Platform, extract-transform-load (ETL) scripts, and asynchronous events, we found a solution that met all of ACME’s requirements and constraints.
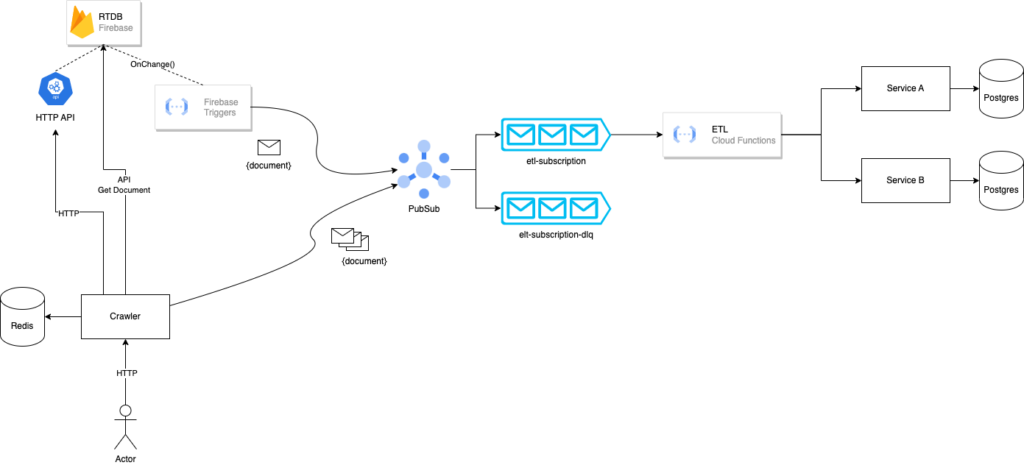
The components:
- RTDB Crawler – A custom application written to crawl a given Firebase collection and emit messages to Google PubSub. Initiated by an HTTP request, this application would handle performing a bulk migration of documents.
- Firebase triggers – Firebase functions to capture individual changes on documents and emit the document to PubSub.
- Google PubSub – Message broker (topics/subscriptions) for broadcasting documents that are being migrated.
- ETL – Google Cloud function written to transform the data in the message and call the appropriate backend service.
- Services – The new REST backend with Postgres. These are the new destinations for the data coming out of RTDB
(Google Cloud: Google App Engine, Firebase functions, Firebase storage, Google PubSub, Google Functions)
Let’s get crawling!
With this approach, we were able to run a migration in piecemeal–one Firebase collection at a time! Any load on RTDB was brief and was able to handle the crawler scanning all documents in a collection. Since the load on RTDB manageable, the crawling of Firebase collections and migration could be run during normal business hours.
The crawler could perform a migration for an entire collection, while the Firebase triggers captured individual document changes that occurred during or after a migration was complete—thus allowing both systems to remain in sync.
Each time we crawled a Firebase collection, a lot of messages were emitted (in the order of hundreds-of-thousands and sometimes in the millions). PubSub and ETL functions were able to rapidly scale to meet the demands of all the documents that were traveling across the wire. Within minutes, the ETL function would scale from zero instances to a peak of 5000 instances.
Finding the right path
This approach minimizes system load, avoids downtime, and can be run during normal operational windows. That said, we found a few unexpected issues during testing. At this point, it was time to fine-tune the solution to make it robust and reliable for ACME.
Connection unavailable
The first issue encountered was a bottleneck with Postgres. While we had great scalability with PubSub, our ETL Cloud Function, and back-end service (thanks to containers!), there was a limit on the connections to the Postgres database. We allowed our services to scale up beyond the capacity of what the Postgres database could handle. Automatic scaling is ideal to support the customer needs, but in this instance it was detrimental. We started seeing errors in the logs and messages were being sent to the Dead Letter Queue.
This was resolved by adding a maximum number of instances to the ETL Cloud Function. It was great to scale the instances to 5000, but that also flooded the requests into the services, thereby flooding Postgres. However, the change to the ETL also had a cascading effect on PubSub due to the push message configuration for the topic and subscription. To compensate for this, we introduced a throttle into our RTDB Crawler so that we would not flood PubSub, thereby overwhelming either the ETL or Service. A minimum of 25ms before each message was sent to PubSub did the trick! The trade-off was that crawling the collections now took slightly longer.
A pile of messages
The second issue was that the Dead Letter Queue (DLQ) filled up rapidly and was difficult to triage. All the messages in the DLQ represented a point in time for the data that was in the message. We ran the risk of applying old or stale data to our service if we tried to re-publish the same message. But this also left our service in a state where it is no longer in sync with RTDB. This required a fundamental shift in how and where we were pulling data from RTDB.
In its current state, both the Crawler and Firebase Functions would retrieve the document and embed it in the message sent to PubSub. The ETL would parse the document and send it the service via HTTP. By changing the message payload to include only document identifiers, the ETL could be leveraged to retrieve the document from Firebase. This change ensured that we were always dealing with the latest document from RTDB.
What about the messages in the DLQ? Since the messages only included document identifiers, this enabled us to “replay” messages in the case of a failure. We authored a script to move the messages from the DLQ back to the topic/subscription, thus replaying the same message. In the event of failures, we were able to preserve data integrity between systems and have both data stores in an eventually consistent state.
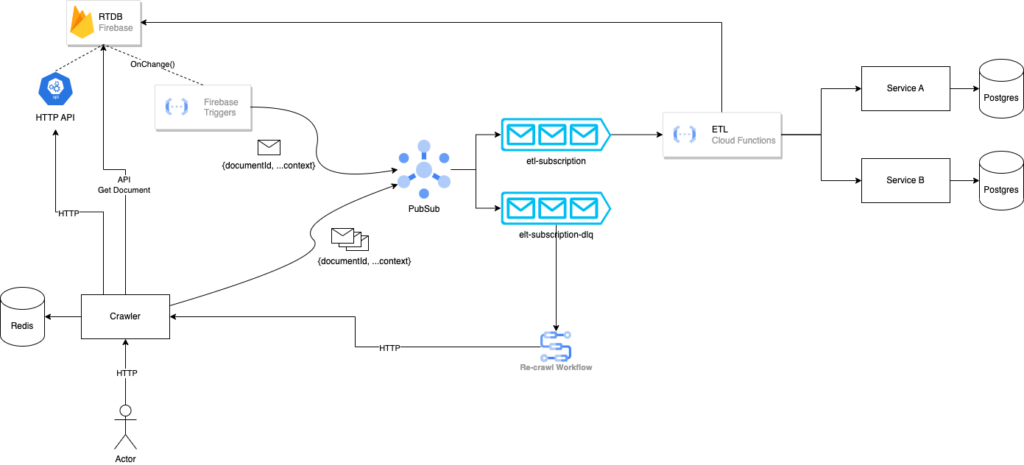
After making a few key changes to the architecture, the migration process became more reliable and stable.
- Metered traffic to PubSub and ETL provided more stability
- Messages in the DLQ dropped dramatically
- The ability to replay messages ensured integrity between systems
Additional problems and notes
At times, the ETL was difficult to author because the data models between RTDB and the services were vastly different. Careful design, thorough code-reviews, and testing ensured that complex documents were successfully migrated.
Firebase Functions and PubSub were not always reliable. Due to rate limits or hiccups in the Google infrastructure (yes, it happens!), we had to build different fallbacks to ensure messages were sent to PubSub. While a clear root cause was not identified, we were able to work around the issue by creating a special endpoint in the Crawler that could be called to migrate a single document. If the Firebase function failed to publish a message to PubSub, it would then execute an HTTP request to our Crawler for the document.
We monitored all our activities through a custom dashboard on DataDog. We were quickly able to see how a migration effort was progressing, any errors, and how many messages were in our DLQ. Observability for the entire migration processes was absolutely a key component for success! Not only were we able to see what was happening with the migration, it provided a nice visual to ACME stakeholders as well.
A journey’s end
Data migrations are never easy and migrating between NoSQL and RDBMS platforms is a challenge. Being able to leverage Cloud technologies created the possibility of a seamless migration for ACME. Axian was able to successfully meet all of ACME’s requirements and enable the development of their new platform. In the end, the ACME was able to successfully migrate their data out of RTDB without any downtime and make it available in their new platform.