
Recently we were presented with a greenfield project from a client with an interesting blend of performance requirements and desired architecture pattern. Our client wanted a highly available, autoscaling microservice with excellent performance across North America, delivered using serverless technologies in the AWS cloud. The solution that we developed for this project is something we are proud of and close enough to a “best practice” that we will be replicating and modifying for future projects with similar needs.
Some of the key requirements that drove this design:
- One of the consumers of this service was a mobile device application that needed to fetch account information before it would load. Any slowness in this exchange would have far reaching customer satisfaction implications.
- Consumers of this service would be making calls from all over the US and Canada, coast to coast.
- Our client was moving to microservices across the organization and wanted to ensure reliable API documentation was available to all technical teams.
Let’s talk speed
Lambdas can execute simple operations extremely fast, given the right configuration and programming. We wanted to leverage this speed as much as possible, but within the framework of an API we knew we would have to make some sacrifices. We spent a few sprints iterating on design concepts and testing various lambda configurations to ensure the best possible configuration.
What we discovered:
- Memory allocation also determines how much processing power your lambda is allocated, so we would need to run at least 512mb lambdas to ensure the most efficient cold start time and general run time (this is also somewhat language dependent)
- Cold start time is also impacted by the general startup time of your code, and a big contributor to that are API frameworks and other dependencies your code requires. We decided to completely nix the API framework and utilize native API Gateway functionality instead to keep our functions lean
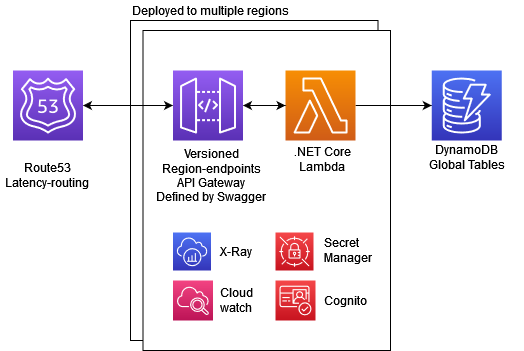
The Architecture
The result of this investigation was an architecture design that utilizes fully defined API Gateway routes integrated with pure lambda functions. The stack consists of the following AWS resources (see diagram below):
- Route53 (Latency based routing)
- API Gateway
- Cognito (API gateway native authorizer)
- Lambda
- Secrets Manager
- DynamoDB (with Global tables)
- CloudWatch & X-Ray
Terraform
Terraform (an infrastructure as code framework) is utilized to define and deploy all the AWS resources in a consistent and repeatable manner. The entire API is defined in a terraform module that is deployed per AWS region defined by a simple variable. Remote state is used to ensure all environments can be updated and torn down at will, as well as ensure developers can share workspaces, making it extremely simple for a new developer to spin up their own test environment.
Swagger
One of the challenges of using native API Gateway routes with individual, integrated lambdas is managing all the configuration of each specific route. Luckily API Gateway provides the capability to define and deploy an API from a swagger document, generating all the routes, models, validation, authorizers, and integrations automatically. The challenge is ensuring the swagger document is accurate and kept up to date.
Our solution was to build a “dummy” API definition project alongside the rest of the source code. This project utilized all the same objects and entities the lambda projects use, simply existing as a strict definition of the API contract, as if it were sitting in front of the lambdas, but in reality, doing nothing but generating a swagger document on build.
Because it’s in the same project, and our language of choice is strongly typed, it enforces accuracy and consistency, and since swagger is required to deploy the service, it also ensures our documentation remains completely up to date. If we don’t update the API definition project, it won’t generate the right swagger, and the endpoint won’t deploy correctly and will fail QA.
Multi-region Latency Based Routing
To ensure the best performance for every consumer, we want the API available in multiple regions. Since the entire stack is defined by terraform and modularized, we can deploy regional versions of the API gateway and lambdas in as many regions as we need. Each API is deployed as a regional API with a custom domain name, and Route53 is configured to use latency-based routing to send each request to the fastest API. All Dynamo tables are deployed as global tables and replicated to all defined regions.
Availability & Scaling
With the latency-based routing policy, if a region goes down for any reason, Route53 will simply send the traffic to the closest region that is still up. This may slightly degrade performance, but the system remains available. And because the entire stack is serverless, there is virtually no cost to deploy to as many regions as you want, you only pay for the traffic you use (the only caveat to this is the dynamo global tables, as all data must be replicated to all regional tables, so depending on your implementation this could become costly).
Since the entire stack is serverless, any region can scale as much as needed based on demand, and since we’ve optimized cold-start time on lambdas, scaling up has minimal impact on overall performance. All layers of the stack (APIg, Lambda, DynamoDB) are designed to essentially scale infinitely based on demand, but also have configurations to allow for capping and controlling the scaling if costs become an issue.
What’s Next?
Have we designed the epitome of modern serverless architecture? Of course not. Does such a thing even exist? But this particular design is packageable, reproducible, and checks a lot of “commonly asked for” boxes from our customers. It utilizes the latest cloud technologies to deliver a high quality, highly available, scalable serverless microservice with dependable documentation and is extremely easy to port to other projects. We plan on continuing to iterate on this design to make it increasingly better and to deliver even more value to our clients and partners.