
In 2020, enterprise spending on cloud infrastructure surpassed spending on on-premises data centers for the first time. This watershed milestone highlights the significant shift to the cloud for organizations across the globe.
For some companies, the migration to the cloud entailed like-for-like replication of on-premises infrastructure into a cloud environment. While this is a good first step in realizing some of the benefits the cloud can offer, it fails to embrace the truly transformational benefits inherent in cloud-native infrastructure and applications.
Nautilus recognized the value of cloud infrastructure and had been migrating their on-premises server infrastructure to Amazon Web Services (AWS) for some time. In 2020, Nautilus set a vision for transforming its mission-critical ecommerce transaction gateway to take full advantage of a cloud-native architecture.
Nautilus began their journey by partnering with Axian and leveraging their significant experience with AWS, setting an ambitious vision for a more scalable, resilient architecture. Axian is an AWS Select Consulting Partner that builds critical infrastructure, applications, and websites/portals for customers.
Nautilus had plans to modernize their legacy Microsoft .NET architecture to improve application performance when they experienced a surge in demand for home fitness solutions. In this post we will, discuss how Nautilus looked to Amazon Web Services (AWS) and Axian to develop an enterprise-class architecture that would rapidly scale while delivering an enhanced customer experience.
The Challenge
The original gateway architecture was established by Axian some 15 years ago and, although it had been continuously updated as the associated application portfolio evolved, it did not scale well to accommodate peak business volumes and became an area of technical debt.
The system was a combination of Windows Services (.NET), SQL Server instances, and Webforms UI, whose function was to queue up order, lead, and quote records from various sources and import them into the necessary backend systems.
The original architecture was prime for modernization given recent cloud technology developments. The system itself was robust, but it was monolithic and had to be continually patched to be able to communicate with external systems as they were updated.
Although the application was capable of instantiating multiple services, each service was constrained to process a single document per pass. Over time, as Nautilus’ sales volumes and digital customer interactions increased, the system often failed to keep pace and transactions were queued and became backlogged. As well, it became increasingly more complex to maintain.
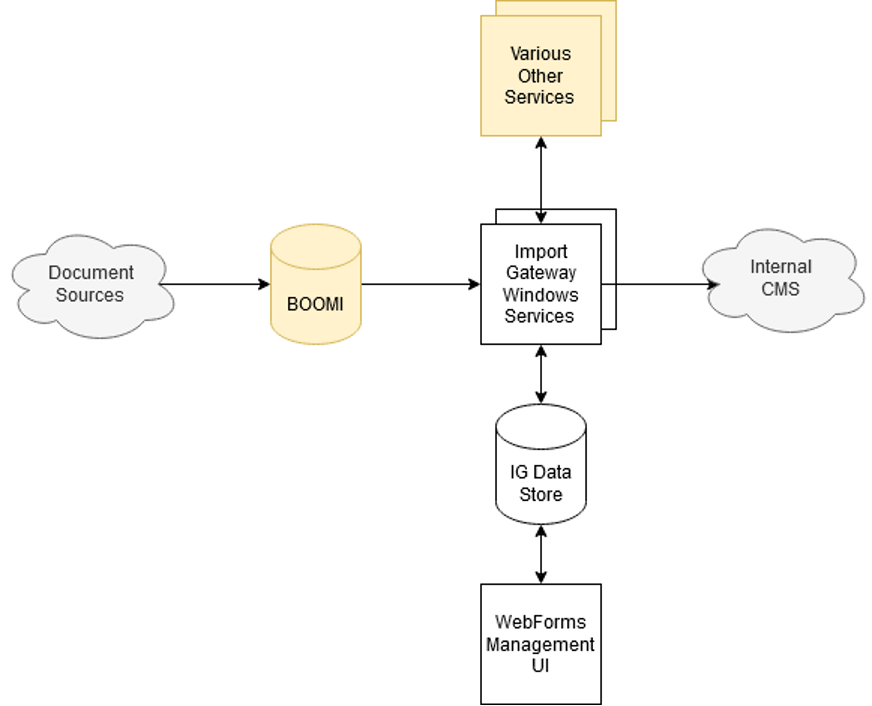
Figure 1 – Original solution (hosted in Windows EC2s).
Project Goals
Through a series of in-depth discovery, design, and planning sessions, Nautilus and Axian collaborated to establish a set of goals and targets that would define the success of the replacement application.
- Build a fully cloud-native solution
- Significantly increase capacity and scalability
- Improve resiliency and visibility
- Better process management
- Eliminate technical debt
- Develop more reliable third-party application interactions
New Cloud-Native Architecture
The solution envisioned utilized AWS Step Functions to move incoming documents through the various steps necessary to be properly imported into all internal systems. The function consists of steps coordinating: direct Amazon DynamoDB interactions, submitting work to AWS Lambda functions, or passing work to a child step function (that in turn utilizes DynamoDB and Lambdas).
There is a primary Step Function for each main process. A “run” of a given step function is triggered by a Lambda that runs on a schedule via an Amazon CloudWatch event, picks up any pending documents, moves them to DynamoDB, and then initiates a new step function execution.
As a document progresses through the steps, it’s frequently updated in DynamoDB. There is a Lambda in place that utilizes DynamoDB streams to replicate the most recent known version of a document into a read-only reporting Relational Database Service.
The following AWS services were used to build the new architecture:
- AWS Step Functions: Each type of record (Order, Quote, Lead, etc.) would have a “pipeline” defined and executed using the AWS state machine solution. Various steps would utilize both Lambdas and direct DynamoDB calls to orchestrate as necessary.
- AWS Lambda: Any orchestration with outside systems or complex logic would be performed within an isolated .NET core Lambda.
- Amazon DynamoDB: While a record is being processed, all information about that record and its state would be stored in DynamoDB for easy update and retrieval.
- Amazon API Gateway: All service calls to NetSuite would be proxied through Amazon API Gateway to provide tracking and throttling capabilities.
- Amazon CloudWatch and AWS X-Ray: Utilize the best of AWS monitoring solutions to provide as much visibility as possible.
- Amazon RDS: A small MySQL database as a read replica of the DynamoDB tables for time-based reporting and metrics.
- AWS Secrets Manager: Hosting all secrets in a shared location.
- AWS CodePipeline and AWS CodeBuild: For CI/CD of each of the environments.
- Amazon CloudFront and Amazon S3: For hosting of the new front-end application (React).
- Amazon Cognito: For authorization and authentication concerns, connected to the customer’s Active Directory.
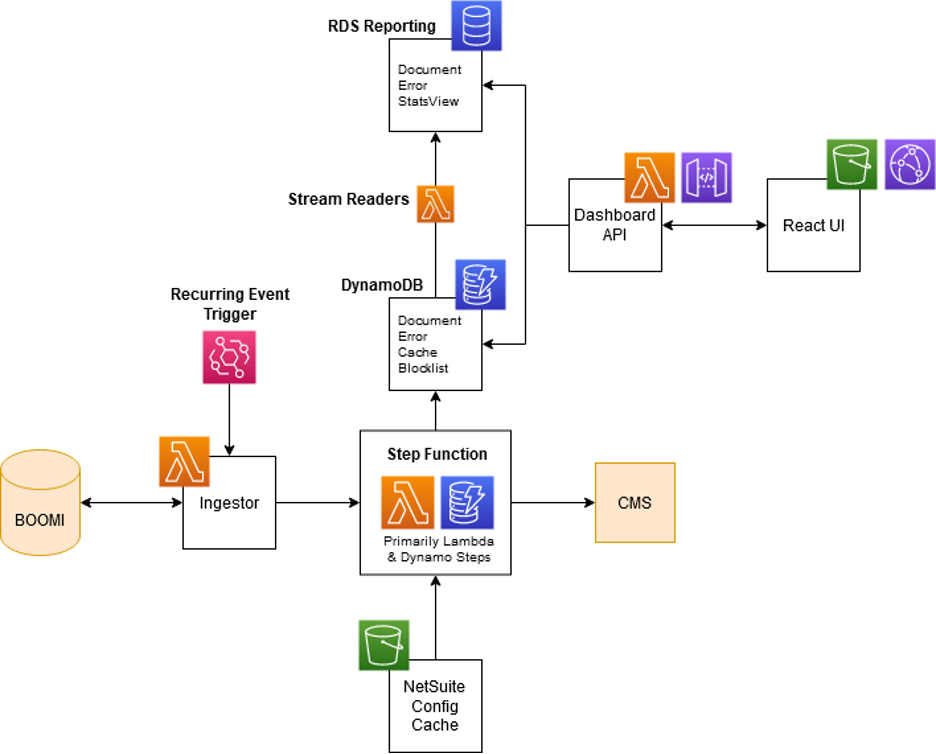
Figure 2 – New solution architecture, cloud native, mostly serverless.
Error Handling and “Replayability”
One of the main features of the original system was its error handling and resolution. It was a robust, self-healing system that would automatically seek to resolve errors and resume processing, only stopping if it encountered a new or unsolvable error. This inherent resiliency was a baseline requirement for the new system.
AWS Step Functions provided this capability in a few notable ways. The built-in try/catch/retry system allowed us to implement customized retry loops for various errors, providing increased control with little configuration code.
The built-in callback functionality allows us to “pause” and hand off workloads to other systems, which, when finished, will “callback” into the step function and tell it to resume.
Through CloudWatch events, the system monitors specifically for Step Function errors, which trigger our default error reporting Lambda which, in turn, exposes the error in the same way as “in-function” errors.
For any error that occurs, the system can either resume the specific Step Function execution at the last step attempted or start a new execution of the Step Function from the exact step where it failed.
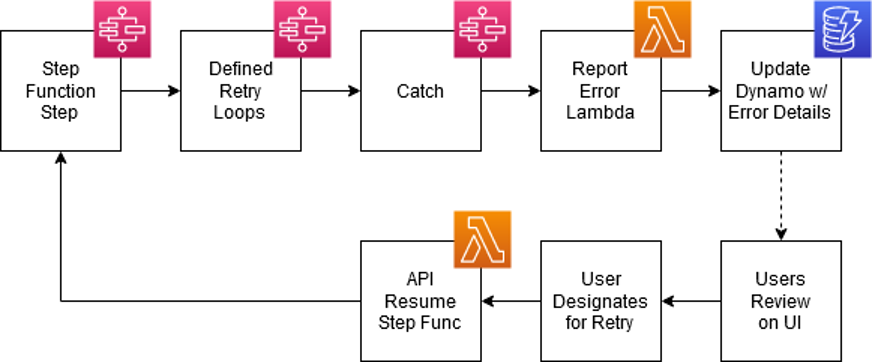
Figure 3 – Pausing step functions on error, and resuming them after manual intervention.
Scalability and NetSuite Concurrency Handling
Thanks to the nature of serverless architecture, the step functions and Lambdas can horizontally scale on a massive level, allowing for parallel processing that would have been impossible for the previous system.
As a result, any limitations are defined by the performance, concurrency capability, and request capabilities of the various integrated applications. The primary integration is to Nautlius’ business systems, which have a limited number of concurrent connections that are shared across the organization.
The solution is able to throttle throughput via a scheduled Lambda that precedes the Step Functions and limits the number of concurrent executions that can be scaled as necessary to accommodate priority and seasonal demand.
CI/CD, Terraform, and DevOps
The current AWS serverless offerings provide great tools and capabilities for developing CI/CD pipelines for a single serverless resource, or a few resources coupled together. However, this new system posed a unique challenge by requiring a very large set of serverless resources (Lambdas, state machines, DynamoDB tables, topics and queues) to be maintained and deployed in tandem.
The Terraform framework was utilized to enable the mass deployment of all necessary resources at the same time and in the proper sequence. AWS CodePipeline orchestrates a standard build, test, and deploy pattern triggered off of GitHub push requests for each environment (dev, qa, stage, production), with the “deploy” step consisting of an AWS CodeBuild task that runs terraform CLI commands to publish the stack.
Terraform keeps track of the current state of each environment in an Amazon S3 bucket and only deploys what has changed since the last release. This enables relatively quick and simple “push button” releases with minimal system downtime (in some cases, none).
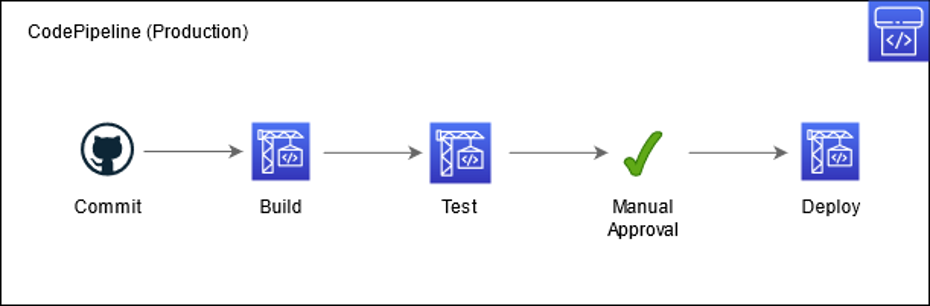
Figure 4 – CodePipeline process for deploying to production.
Visibility, Reporting, and User Intervention
The user interface was built as a React Single Page Application (SPA) consisting of a main dashboard page with top-level metrics and current error list, search page, and record detail page.
Amazon DynamoDB streams are utilized to replicate documents to a read-only reporting MySQL RDS for time-based queries to support searching and filtering.
Near real-time visibility into the health of the system is provided by a MySQL scheduled event that queries the reporting database and logs key metrics including: the number currently in process, in error, the average processing time, and the average system throughput.
The UI polls the log on at the same frequency and displays it to all users. Coupled with other static statistics, this provides an entirely new level of visibility into the system’s performance in near real-time.
Axian also developed specific CloudWatch dashboards to combine metrics and logs from all the various AWS resources being utilized to give support staff a holistic picture into how the cloud stack is performing in any particular area.
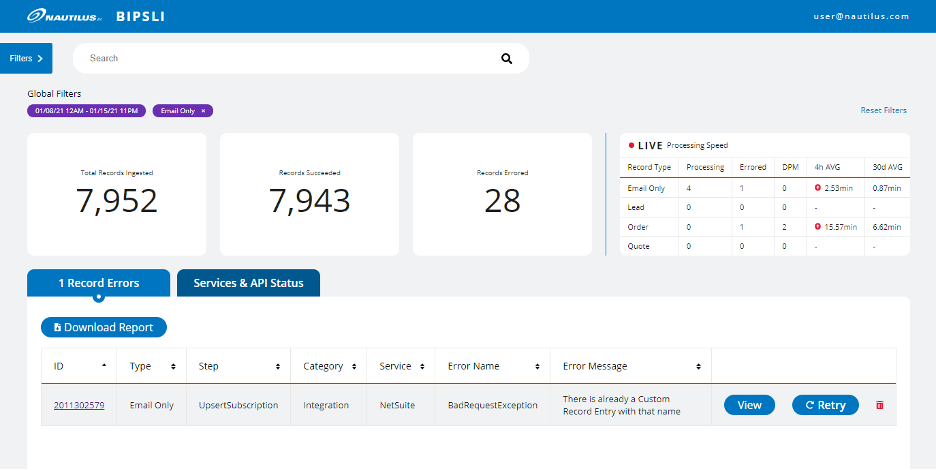
Figure 5 – New UI for reporting, metrics, and manual remediation of process errors.
Stretch Goal
Although it was aggressive, the goal was set to complete the Orders portion of the new application before the Thanksgiving holiday, the start of Natulius’ traditionally seasonal business peak.
In 2020, Nautilus saw increases in product orders across the board and the team’s expectation was holiday shopping would put the existing system under a level of strain dwarfed by anything it had seen prior. Getting the new system online was paramount to ensure customers have the best possible experience with their holiday orders.
The new application, tagged BIPSLI, was released the Tuesday before Black Friday. The combined team monitored the application over the course of the next day and half to be sure the system was functioning as designed and, by Black Friday, product orders spiked significantly and the system performed beautifully.
The step functions and Lambdas scaled perfectly to the exact number of executions desired, and the load was maintained as high as possible to fully utilize the available connections. Ultimately, BIPSLI matched pace with the order load the entire weekend.
This result was a massive improvement in performance that exceeded all expectations. BIPSLI had achieved performance between 10-20x what the old system had been able to do, without hitting maximum capacity.
Not only did it meet and exceed expectations for the highest order load of the year, but it gave every indication it will be able to do even more as Nautilus continues to grow over the years to come. In Figure 6, you can see that over the Black Friday weekend, BIPSLI completely kept up with orders flowing from the public site (Blue/Gray), in comparison to the old system, which could only process the same amount of records synchronously (Orange). Notice at the end, there was a backup in the database in front of BIPSLI, which when resolved, BIPSLI immediately processed all pending documents and continued as normal.
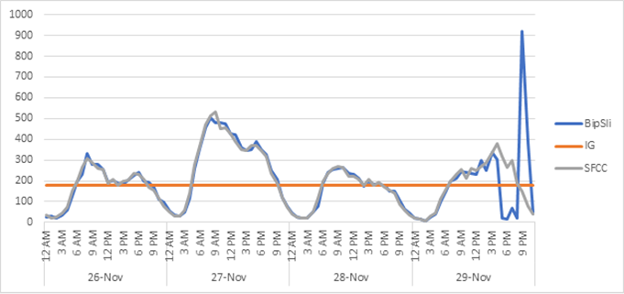
Figure 6: Black Friday weekend BIPSLI vs IG system performance
This outstanding result is in large part due to the complete investment in, and adoption of, serverless architecture by Nautilus.
By distributing the load of an ETL process of this nature across many small, serverless applications, orchestrated by step functions, the system is able to scale horizontally as load demands without worrying about the usual constraints inherent with typical server-based solutions approaching maximum capacity.
In this specific case, BIPSLI is only limited in this scaling by constraints of other third-party systems. As development is able to refactor those constraints, this system should scale to accommodate even higher loads.
BIPSLI allows Nautilus to keep pace with order and lead volumes, ultimately enabling them to better serve their customers. For Nautilus and Axian, BIPSLI was a technical success and a win for Nautilus’ customers and that is truly exciting.
Conclusion
Nautilus’ commitment to invest in an innovative, fully cloud native platform for their replacement system enabled Axian to design and develop a product that is truly best in its class.
Achieving significant scaling and capacity improvements, far greater resiliency, reliability, and transparency, more powerful process management, a complete erasure of decades of technical debt, and a base platform that is ready to scale with the business for years to come, all powered by the latest versions of AWS Lambda, DynamoDB, Step Functions, RDS, CodePipeline, Cloudfront, and other serverless services.
Nautilus, and this new platform, are a perfect real world case study of how the AWS serverless cloud can modernize, revolutionize, and transform enterprise business processes and applications.